With a lot of battery-powered ZigBee devices on my home network (thermostats, contact sensors, remote controls, etc) it’s useful to have an Home Assistant dashboard with the status of all the batteries, to change the ones before the device goes off.
Simple task, with an Entities Card:
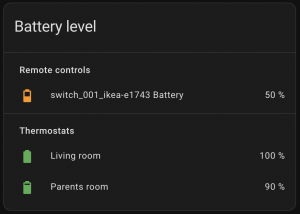
type: entities
title: Battery level
state_color: true
entities:
- type: section
label: Remote controls
- entity: sensor.switch_01_ikea_e1743_battery
- type: section
label: Thermostats
- entity: sensor.thermo_001_battery
name: Living room
- entity: sensor.thermo_002_battery
name: Parents roomWith the following result:
But this approach has three main drawbacks:
- Every time a new devices is added to the network, the card needs to be updated
- Even if the colors help to identify at a glance the batteries that need to be replaced, the search is still a manual process
- It cannot be automated, for example sending a message every time a battery goes under a certain level
Templates to the rescue
Here a Markdown card with a template that identify all the entities in the system tracking battery level, find the ones with a value below a certain number, and list them:
type: markdown
content: |
{#- Find all the battery sensors -#}
{%- set sensors = expand(states.sensor)
| rejectattr('state', 'in', ['unavailable', 'undefined', 'unknown'])
| selectattr('attributes.device_class', 'defined')
| selectattr('attributes.device_class', '==', 'battery')
| rejectattr('entity_id', "search", "keepout_8p")
| selectattr('attributes.unit_of_measurement', 'defined')
| selectattr('attributes.unit_of_measurement', '==', '%')
| list %}
{#- Show only the entities with a battery level below a certain threshold -#}
{%- for s in sensors -%}
{%- if s.state | int(0) < 30 -%}
{{ s.attributes.friendly_name + ": " + s.state }}
{#- s.entity_id can be used too #}
{% endif -%}
{% endfor -%}
title: Devices with low battery levelWith this final result:

Let’s look at the code block by block.
Find all the entities measuring a battery level
{#- Find all the battery sensors -#}
{%- set sensors = expand(states.sensor)
| rejectattr('state', 'in', ['unavailable', 'undefined', 'unknown'])
| selectattr('attributes.device_class', 'defined')
| selectattr('attributes.device_class', '==', 'battery')
| rejectattr('entity_id', "search", "keepout_8p")
| selectattr('attributes.unit_of_measurement', 'defined')
| selectattr('attributes.unit_of_measurement', '==', '%')
| list %}First, the expand() command returns all the sensors in the system, then a series of Jinja 2 filters are applied to remove unavailable, undefined and unknown entities, find all the entities with a battery device class, remove entity_id of my phone (keepout_8p) and find all the remainig entities with the % as unit of measurement of the battery.
Find all the battery level below a certain threshold
{#- Show only the entities with a battery level below a certain threshold -#}
{%- for s in sensors -%}
{%- if s.state | int(0) < 30 -%}
{{ s.attributes.friendly_name + ": " + s.state }}
{#- s.entity_id can be used too #}
{% endif -%}
{% endfor -%}A simple check for all the sensors found previously, to identify if there are battery levels below a certain threshold. To be sure a comparison between numbers is done, the state value is parsed as integer, and then compared with the threshold level. Once the entity is identified, the message to show is assembled, chaining different property of the sensor.
A template sensor with the devices
To get the information, but inside an sensor, it could be useful to create a template sensor. The logic is the same:
template:
- sensor:
- name: ZigBee devices battery to change
unique_id: zigbee_devices_battery_to_change
state: >
{#- Find all the battery sensors -#}
{%- set sensors = expand(states.sensor)
| rejectattr('state', 'in', ['unavailable', 'undefined', 'unknown'])
| selectattr('attributes.device_class', 'defined')
| selectattr('attributes.device_class', '==', 'battery')
| rejectattr('entity_id', "search", "keepout_8p")
| selectattr('attributes.unit_of_measurement', 'defined')
| selectattr('attributes.unit_of_measurement', '==', '%')
| list %}
{#- Show only the devices with a battery level below a certain threshold -#}
{%- for s in sensors -%}
{% if s.state | int(0) < 30 %}
{{ s.attributes.friendly_name + ": " + s.state }}
{#- s.entity_id can be used too -#}
{% endif -%}
{%- endfor -%}




